
Under the Hood of FitzPredict
You can find the files here.
Step 1: Scrape the training data using BeautifulSoup
Without access to a Test cricket database, I had to build my own data set. Fortunately, Cricinfo Statsguru came to the rescue. I used Python’s BeautifulSoup package to scrape the result data (the model target) and fall-of-wicket data (the model features) to create the training set.
In the interests of simplicity, I made two decisions to limit the scope of the model:
- Predict only the results of completed matches. Although predicting draws would be great, it would require extra contextual data as well as a more sophisticated model structure.
- Fit a parsimonious model of win likelihood, with three features only: innings number, number of wickets lost, and number of runs ahead or behind the opposition.
The modeling data set contained one row per unique score in the match. For example, Australia began the third innings of the 2020-21 Boxing Day Test 131 runs in arrears. They scored four runs before losing the first wicket. The first six rows of training data are thus:
| match_id | innings | runs_diff | wickets | win_ind |
|---|---|---|---|---|
| 2398 | 3 | -131 | 0 | 0 |
| 2398 | 3 | -130 | 0 | 0 |
| 2398 | 3 | -129 | 0 | 0 |
| 2398 | 3 | -128 | 0 | 0 |
| 2398 | 3 | -127 | 0 | 0 |
| 2398 | 3 | -127 | 1 | 0 |
Step 2: Fit the model using scikit-learn
The model was trained on post-World War I data because batting averages stabilised after this point.
A logistic regression model was fit. Importantly, the modeled curves are monotonic with respect to wickets and runs. This guarantees that a team’s likelihood of winning will increase when it scores a run or takes a wicket.
Equally importantly, the model fits the test data well.
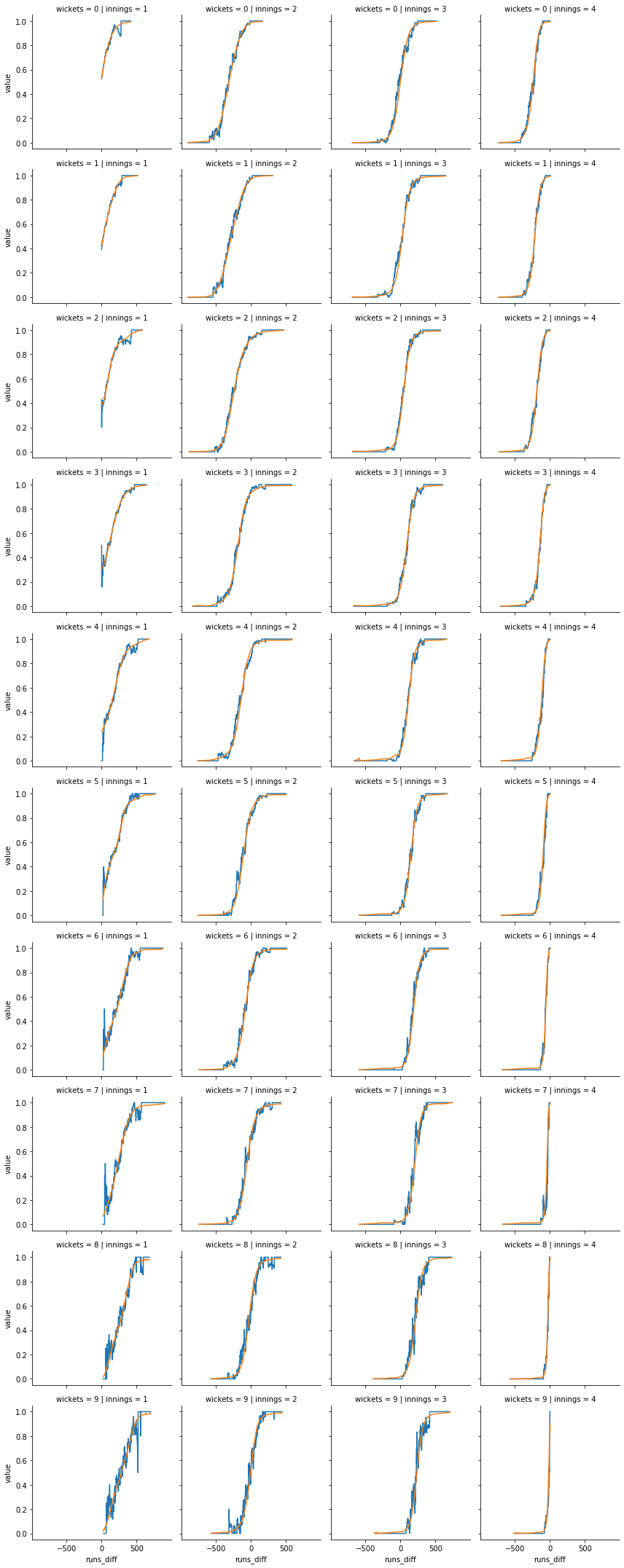
Step 3: Deploy the model using Flask
I created a program to scrape Cricinfo live match scorecards, parse the features, and score the model.
I followed this tutorial for the Flask deployment. It was hosted on PythonAnywhere.